网络出版地址:/kcms/detail/11.2442.N1300.004.html北京大学学报(自然科学版)Acta Scientiarum Naturalium Universitatis Pekinensisdoi: 10.13209/j.0479-8023.2016.024基于PMI 改进算法的新词发现对中文分词系统改进†杜丽萍 李晓戈 于根 刘春丽 刘睿西安邮电大学 ,西安 710121; † 通信作者 , E-mail: lixg@摘要 提出一种非监督的新词识别方法。该方法利用互信息(PMI) 的改进算法——PMIk算法与少量基本规则相结合, 从大规模语料中自动识别 2~n 元网络新词(n 为发现的新词最大长度,可以根据需要指定) 。基于 257MB 的百度贴吧语料实验,当 PMIk 方法的参数为10 时, 结果精度达到 97.39%,相对 PMI 方法精度提高了28.79%, 实验结果表明,该新词发现方法能够有效的从大规模网络语料中发现新词。将新词发现结果编纂成用户词典,加载到汉语词法分析系统 ICTCLAS中, 基于 10 KB 的百度贴吧语料实验,相对加载用户词典前的分词结果准确率、召回率和 F 值分别提高 7.93%,3.73%和 5.91%, 实验表明,通过进行新词发现能有效改善分词系统对网络文本的处理效果。
关键词 新词识别 ;未登录词 ; 互信息 ; PMI 改进算法;中文分词中图分类号 TP391New Word Detection Based on an Improved PMI Algorithm for EnhancingSegmentation SystemDU Liping LI Xiaoge† YU GenLIU Chunli LIU RuiSchool of Computer Science and Technology, Xi’an University of Posts and Telecommunications, Xi’an 710121,China;† Corresponding author, E-mail: lixg@Abstract This paper presents an unsupervised method to identify internet new words from the large scale webcorpus, which combines with an improved Point-wise Mutual Information (PMI), PMIk algorithm, and some basicrules. This method can recognize internet new words with length from 2 to n (n is any number as needed).Experimented based on 257 MB Baidu Tieba corpus,the precision of proposed system achieves 97.39% when theparameter value of PMIk algorithm is equal to 10中文分词 新词识别, and the precision increases 28.79%, compared to PMI method.The results show that proposed system is significant and efficient for detecting new word from the large scale webcorpus. Compiling the results of new word discovery into user dictionary and then loading the user dictionary intoICTCLAS (Institute of Computing Technology, Chinese Lexical Analysis System), experimented with 10 KBBaidu Tieba corpus, the precision, the recall and F -Measure were promoted 7.93%, 3.73% and 5.91% respectively,compared with ICTCLAS. The result show that new word discovery could improve the performance ofsegmentation for web corpus significantly.Key words new word recognition; unknown word; PMI; improved PMI algorithm; Chinese word segmentation随着信息时代的发展与科学技术的进步,大量新词识别 已经成为提高分词效果的瓶颈[1] 。

网络新词不断涌现,使得分词结果中存在大量的对于网络上 出现的新词汇,例如近日在网上“散串”, 严重影响了分词系统处理网络文本的效果 ,热传的“APEC蓝” 、“Duang” 、“一带一路” 、“单肾国家自然科学基金,陕西省普通高等学校重点学科专项资金(112-1602)和西安邮电大学研究生创新基金(ZL2013-31)资助2015-09-29 13:00:18收稿日期 : 20150607; 修回日期 : 20150914; 网络出版时间:1 北京大学学报 ( 自然科学版) 贵族”“花样作死 ”等词语 ,一般的识别方法是基于本文在杜丽萍等[13] 的定理 1 和 2 基础上,采用 大规模语料库由机器根据某个统计量自动抽取出候非监督的基于PMIk 与少量的基本规则相结合的方[2] 选 新 词 , 然 后 再 由 人 工 筛 选 出 正 确 的 新 词。法 , 从 大 规 模 网 络 语 料 中 自 动 识 别 新 词 ,并 对 Pecina 等[3]采用 55 种不同的统计量进行 2 元词汇ICTCLAS2002 版分词系统进行改进 ,对比改进后 识别实验 , 结果表明 ,PMI 算法是最好的衡量词汇的 ICTCLAS2002 分 词 系 统 与 ICTCLAS2002 和 相关度的算法之一。

通常情况下,PMI 方法能够很ICTCLAS2015 版的分词效果。 好地反映字串之间的结合强度 ,但 PMI 方法的缺点1 分词系统改进 是过高估计了低频且总是相邻出现的字串间的结合 强度[3–4] 。例如,“啰”和“嗦” 、“蝙”和“蝠”等在语料1.1 改进分词系统框架 库中低频且总是相邻出现中文分词 新词识别,这些字串的 PMI 值非常分词系统改进主要分为两个阶段 :1)基于大规 高 , 包含这些低频字串的垃圾串的PMI 值也非常模语料库进行新词发现 ;2)用新词发现结果编纂用 高 , 例如“很啰 ”和“嗦” 、“ 的蝙”和“蝠”等。针对此户词典, 加载到分词系统中。图1 为改进的分词系 问题, 有些研究者将 PMI 方法与其他方法相结合进统的流程图。 行新词发 现研究 ,文献 [5–7]均采 用PMI 方 法与1.2 基于PMI 改进方法的新词发现k [12] log-likelyhood 方法相结合进行新词识别 ;梁颖红等定义 1 PMI 算法 定义如下:k [8]p x ,y 利用 PMI 方法衡量字串间的结合强度 ,再结合PMIk x, y log , k N , p x p y NC-value 方法融入词语上下文信息来提高三字以 [9]其 中 , p x 和 p y 分 别 表 示 字 串 x 和 y 的 概 率 , 上长新词的抽取精度 ;何婷婷等采用互信息方法 F-MI 抽取结构简单的质词 ;孙继鹏等 [10]提出一种p x ,y 表示字串 x 和 y 的联合概率,PMIk x, y 表 语 言 文 法 信 息 与 互 信 息 相 结 合 的 新 词 识 别 方 法 ;示字串 x 和 y 的相关度,也称 PMIk 值。

特殊地 ,当 Pazienza 等[11]提出使用 PMI2 和 PMI3 的方法改进kk 1 时, PMI 方法即 PMI 方法。 PMI 方法来识别新词 ;Bouma[12]通过向 PMI 方法中新词发现过程主要分为 4 个阶段 :1)确定 2 元 引进 k 个联合概率因子 ,来改善PMI 方法的缺点,待扩展种子 ; 2)将 2 元待扩展种子扩展至 2~n 元 ; 3) 这种改进的 PMI 方法称为 PMIk 方法 ;杜丽萍等[13]过滤候选新词 ;4)人工判定。算法的具体步骤如 通过抽象语料库中低频且总是相邻出现字串的数学下。 特征, 从理论上证明 ,当向 PMI 方法中引进 3 个及步骤 1 从 4 元字串中确定出 2 元的待扩展种 以上的联合概率因子时 PMIk 方法能够克服 PMI 方子。对于每一个4 元字串 ww w w , 计算中间i1 i i1 i2 法的缺点。两元字串 w w和前两元字串 ww 的 PMIk 值之和i i1i1 i目前, 常用的分词方法主要有3 种 : 基于词表 的分词方法、基于统计模型的分词方法和基于统计 方法与规则方法相结合的分词方法[2] 。
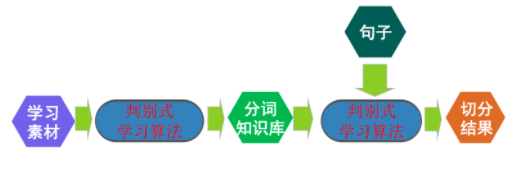
三种方法均 有优点 , 但也存在不足 :基于词表的分词方法效率 高但对新词的识别能力不足[14];基于规则的方法很 难涵盖所有的语言现象 [2],尤其对网络语料的处理 能力非常有限;基于统计模型的分词方法重点在于 解决自动分词的歧义分词问题 ,但需要人工标注训 练 语 料 , 且 受 训 练 语 料 领 域 的 限 制 。 ICTCLAS(Institute of
